モンテカルロ法線量計算
既存の線量計算プログラムに対してポーティングを行い、GPUを用いた並列高速化を実現します。
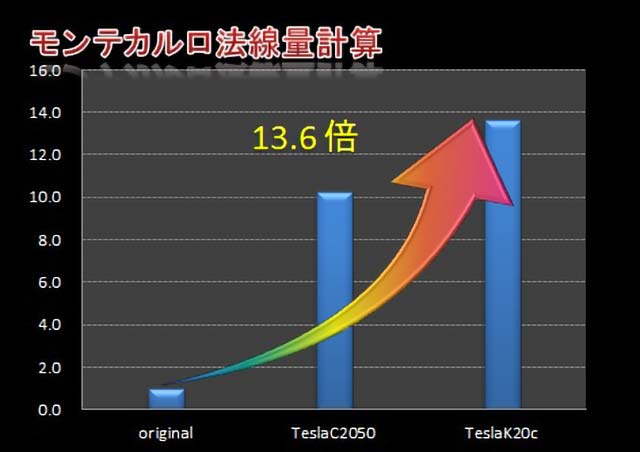
※1 original : Intel® Core™ i7 6Core OpenMP
技術要素
【マシン環境】
- PC-Linux デスクトップ機
【GPGPU】
- NVIDIA 社 Tesla C2050(Fermi), K20c(Kepler)
【OS】
- 64bit CentOS 6.3
【開発ツールおよび言語】
- NVIDIA CUDA コンパイラ(nvcc), CUDA C
詳細
(1) 乱数による計算のため分岐が多い
共有メモリを使用することにより、分岐を軽減します。
⇒ 4~8倍程度の効果
(2) 並列高速化に向けたコード改修
並列度を上げるためにループ統合します。
ワーク変数(レジスタ)を利用して、不必要なアトミック演算を減らします。
⇒ 高速化を実現